들어가며
최근 SW PLC에서 관심 갖고 개발 중인 내용은 Linux PREEMPT_RT 커널을 이용해 실시간성을 보장하는 작업이다.
SW PLC Runtime은 특정 Task를 매 주기마다 실행해야 한다.
따라서 OS에서 프로세스의 실행을 보장받지 못하거나, 처리 속도가 들쭉날쭉 하지 않도록 Jitter를 관리하는 것이 중요하다.
PREEMPT_RT 커널로 실시간성을 확보하고 테스트하는 일련의 과정을 정리해 보려 한다.
용어 및 개념정리 : 2026.03.19 - [개발] - Real-Time, RTOS, PREEMPT_RT, CPU Isolation 개념 정복 - 실시간 처리
Real-Time, RTOS, PREEMPT_RT, CPU Isolation 개념 정복 - 실시간 처리
들어가며'실시간(Real-time)'이라는 용어는 Embedded 및 FactoryAutomation 산업의 핵심이며,현장에서 다양한 관점과 의미로 혼용되곤 한다.또한 자연스럽게 따라오는 '처리 속도'는 모든 SW/HW의 핵심 지표
prejudice.tistory.com
테스트 시나리오 설계
㎱(나노초), ㎲(마이크로초) 단위로 처리하는 Real-Time을 제대로 구현하고 평가하기 위해 테스트 설계 과정이 중요하다.
우선 커널단에서 처리하는 과정은 다음과 같다.


테스트 목표는 Interrupt가 발생한 시점부터 Test Program(=TaskB) 이 호출될 때까지의 Jitter를 측정하고 비교하는 것이다.
목표 달성을 위해 다음과 같이 테스트를 설계했다.
- HW : Linux PREEMPT_RT 커널이 올라간 BoxPC
- 측정 방법 : TaskB를 10㎳ 주기로 10,000회 반복 호출하며 깨어날 때의 시간을 정밀 측정
- 측정 환경 : ① stress-ng 툴로 CPU와 I/O에 강제 부하 인가
② QTimer, non-RT Kernel, PREEMPT_RT Kernel 각각의 조건에서 실행 후 비교 - 예상 결과 :
☐ QTimer는 내부의 QEventLoop 구조로 인해 Linux Basic Kernel 보다 Jitter가 클 것이다.
☐ 강력한 시스템 부하로 인해 QTimer와 non-RT Kernel의 Jitter는 변동폭이 클 것이다.
☐ 반면 PREEMPT_RT Kernel의 Jitter는 극한의 상황에서도 안정적인 수준을 유지할 것이다.
QTimer 프로그램 구현
우선 Qt6를 설치하고 QTimer를 이용해 10㎳마다 timeout 되도록 프로그램을 작성했다.
이때 Qt6.8에 도입된 Qt::PreciseTimer 를 사용해 Jitter 특성을 최소화했다.
(*Precise Timer : https://doc.qt.io/qt-6/ko/qtimer.html)
#include <QCoreApplication>
#include <QFile>
#include <QTextStream>
#include <QTimer>
#include <chrono>
#include <iostream>
#include <vector>
struct LogEntry {
long long tick;
double actualRunTimeMs;
double predictMs;
double gitterMs;
};
int main(int argc, char* argv[]) {
QCoreApplication app(argc, argv);
constexpr double periodMs = 10.0;
constexpr long long totalTicks = 10000;
// 로그 버퍼 사전 할당
std::vector<LogEntry> logBuffer;
logBuffer.reserve(totalTicks);
long long tick = 0;
const auto startTime = std::chrono::steady_clock::now();
QTimer timer;
timer.setTimerType(Qt::PreciseTimer);
timer.setInterval(static_cast<int>(periodMs));
QObject::connect(&timer, &QTimer::timeout, [&]() {
++tick;
const auto now = std::chrono::steady_clock::now();
const std::chrono::duration<double, std::milli> elapsed = now - startTime;
const double actualRunTimeMs = elapsed.count();
const double predictMs = tick * periodMs;
const double gitterMs = actualRunTimeMs - predictMs;
// I/O 없이 메모리 버퍼에만 기록
logBuffer.push_back({tick, actualRunTimeMs, predictMs, gitterMs});
if (tick >= totalTicks) {
timer.stop();
app.quit();
}
});
timer.start();
std::cout << "Started 10ms periodic timer. Logging to timer_log.csv" << std::endl;
app.exec();
// 타이머 루프 종료 후 한 번에 파일 기록
std::cout << "Timer stopped after " << tick << " ticks. Writing log..." << std::endl;
QFile logFile("timer_log.csv");
if (!logFile.open(QIODevice::WriteOnly | QIODevice::Text | QIODevice::Truncate)) {
std::cerr << "Failed to open timer_log.csv" << std::endl;
return 1;
}
QTextStream stream(&logFile);
stream << "index,actual_run_time_ms,predict_ms,gitter_ms\n";
for (const auto& e : logBuffer) {
stream << e.tick << ","
<< QString::number(e.actualRunTimeMs, 'f', 3) << ","
<< QString::number(e.predictMs, 'f', 3) << ","
<< QString::number(e.gitterMs, 'f', 3) << "\n";
}
std::cout << "Log written to timer_log.csv (" << logBuffer.size() << " entries)." << std::endl;
return 0;
}PREEMPT_RT 프로그램 구현
PREEMPT_RT 프로그램도 QTimer와 동일하게,
10㎳ 마다 RT-kernel의 시스템 타이머 인터럽트를 받아 task가 깨어나도록 구현했다.
프로그램의 main 함수 내 while문에서 clock_nanosleep 함수에서 OS호출을 대기하며 블록킹 되는데,
다음과 같은 상황에서는 실시간성을 보장받지 못하고 일반 프로세서와 동일하게 동작한다.
- Linux kernel이 PREEMPT_RT 커널이 아닌 경우
- 실행 시 관리자(root) 권한으로 실행되지 않은 경우
해당 조건을 역이용하여 동일하게 빌드된 단일 프로그램을 통해 non-RT 커널과 PREEMPT-RT 커널 테스트를 모두 진행했다.
#include <cerrno>
#include <cstring>
#include <fstream>
#include <iomanip>
#include <iostream>
#include <pthread.h>
#include <sched.h>
#include <string>
#include <sys/mman.h>
#include <time.h>
#include <vector>
namespace {
timespec addMs(const timespec& t, long ms) {
timespec out = t;
out.tv_sec += ms / 1000;
out.tv_nsec += (ms % 1000) * 1000000L;
if (out.tv_nsec >= 1000000000L) {
out.tv_sec += 1;
out.tv_nsec -= 1000000000L;
}
return out;
}
double diffMs(const timespec& a, const timespec& b) {
const long sec = a.tv_sec - b.tv_sec;
const long nsec = a.tv_nsec - b.tv_nsec;
return static_cast<double>(sec) * 1000.0 + static_cast<double>(nsec) / 1000000.0;
}
struct LogEntry {
long long tick;
double actualRunTimeMs;
double predictMs;
double gitterMs;
};
} // namespace
int main(int argc, char* argv[]) {
constexpr long periodMs = 10;
constexpr long long totalTicks = 10000;
int rtPriority = 80;
if (argc >= 2) {
rtPriority = std::stoi(argv[1]);
}
// 메모리 페이지 폴트 방지: 모든 메모리를 RAM에 고정
if (mlockall(MCL_CURRENT | MCL_FUTURE) != 0) {
std::cerr << "Warning: mlockall failed (" << std::strerror(errno)
<< "). Page faults may cause jitter." << std::endl;
} else {
std::cout << "mlockall: memory locked." << std::endl;
}
// 로그 버퍼 사전 할당 (루프 전에 메모리 확보)
std::vector<LogEntry> logBuffer;
logBuffer.reserve(totalTicks);
sched_param schParam{};
schParam.sched_priority = rtPriority;
if (pthread_setschedparam(pthread_self(), SCHED_FIFO, &schParam) != 0) {
std::cerr << "Warning: failed to set SCHED_FIFO priority=" << rtPriority
<< " (" << std::strerror(errno)
<< "). Continue with current scheduler." << std::endl;
} else {
std::cout << "SCHED_FIFO enabled with priority=" << rtPriority << std::endl;
}
timespec startTs{};
if (clock_gettime(CLOCK_MONOTONIC, &startTs) != 0) {
std::cerr << "clock_gettime failed" << std::endl;
return 1;
}
std::cout << "Started RT periodic task at 10ms. Logging to rt_task_log.csv" << std::endl;
long long tick = 0;
// RT 루프: I/O 없이 메모리 버퍼에만 기록
while (tick < totalTicks) {
++tick;
const timespec targetTs = addMs(startTs, static_cast<long>(tick * periodMs));
const int sleepRet = clock_nanosleep(CLOCK_MONOTONIC, TIMER_ABSTIME, &targetTs, nullptr);
if (sleepRet != 0 && sleepRet != EINTR) {
std::cerr << "clock_nanosleep failed: " << std::strerror(sleepRet) << std::endl;
break;
}
timespec now{};
clock_gettime(CLOCK_MONOTONIC, &now);
logBuffer.push_back({
tick,
diffMs(now, startTs),
static_cast<double>(tick * periodMs),
diffMs(now, addMs(startTs, static_cast<long>(tick * periodMs)))
});
}
// RT 루프 종료 후 한 번에 파일 기록
std::cout << "task stopped after " << tick << " ticks. Writing log..." << std::endl;
std::ofstream logFile("rt_task_log.csv", std::ios::trunc);
if (!logFile.is_open()) {
std::cerr << "Failed to open rt_task_log.csv" << std::endl;
return 1;
}
logFile << std::fixed << std::setprecision(3);
logFile << "index,actual_run_time_ms,predict_ms,gitter_ms\n";
for (const auto& e : logBuffer) {
logFile << e.tick << ","
<< e.actualRunTimeMs << ","
<< e.predictMs << ","
<< e.gitterMs << "\n";
}
std::cout << "Log written to rt_task_log.csv (" << logBuffer.size() << " entries)." << std::endl;
return 0;
}⚠️트러블 슈팅 : 로깅 방식으로 인한 지연
위 예제 코드를 보면 vector::logBuffer에 결과를 담아두었다가 측정(10,000회)이 완전히 종료된 후 일관적으로 파일에 쓰도록 구현했다.
Real-Time 프로그램 원칙 중 disk I/O 작업을 지양해야 한다는 룰이 있다.
㎛ 수준으로 즉각 동작해야 하는 시스템 특성상, 순간적인 파일 입출력 병목이 발생하면 수 ㎳ 이상의 스레드 지연을 초래할 수 있기 때문이다.
초기에 측정 데이터를 실시간으로 보겠다는 마음으로 while 반복문 안에서 매 틱마다 로깅을 수행했다가 지연이 발생했고,
마치 Jitter가 발생한 것처럼 보이는 착시를 겪은 후 메모리 버퍼 방식으로 변경했다.
성능 비교 환경 설정
우선 BoxPC에 PREEMPT_RT Linux kernel을 활성화해야 한다.
Linux 6.12 버전부터는 PREEMPT_RT가 공식 커널에 합쳐졌기 때문에, 최신 배포판을 사용 중이라면 쉽게 활성화할 수 있다.
다만 내가 사용한 Ubuntu 24.04의 커널은 6.8 버전으로 공식적으로 통합되기 이전의 빌드였다.
따라서 커널 소스와 해당하는 버전의 RT 패치를 다운로드한 뒤 직접 빌드하여 커널을 올려주었다.
테스트를 위한 전체적인 OS 환경 세팅은 AI 도구들을 사용하면 훨씬 수월하게 구축할 수 있다.
성능 비교에 앞서 정확한 측정을 위해 두 가지 환경 설정이 더 필요하다.
첫 번째, 스트레스 테스트 도구인 stress-ng를 이용해 시스템 자원 전체에 고의적인 부하를 걸고 측정했다.
Jitter가 튀기 가장 좋은 가혹 환경을 만들기 위해 아래 명령을 사용했다.
| 옵션 | 효과 | RT jitter 유발 메커니즘 |
| --cpu 0 | 모든 코어 CPU 100% 연산 | ☑ 컨텍스트 스위치 유발 |
| --vm 4 --vm-bytes 1G | 메모리 할당/해제 반복 | ☑ 페이지 폴트, TLB flush 유발 |
| --io 4 | 디스크 read/write 반복 | ☑ I/O IRQ 유발 |
| --timer 4 | 타이머 인터럽트 생성 | ☑ 하드웨어 타이머 ㅁ인터럽트 경합 |
| --switch 4 | 컨텍스트 스위치 폭탄 | ☑ 프로세스 스케줄링 간섭 |
| --timeout 120s | 120초간 지속 | ☑ 테스트 기간(약 100초 = 10㎳ * 10,000) 동안 유지 |
두 번째, CPU 동적 클럭 제어 비활성화 PREEMPT_RT에서 clock_nanosleep함수로 깨어나는 순간,
절전 모드 등 cpu 코어의 동작 클럭이 낮아져 있다면 다시 연산 클럭을 끌어올리는 과정에서 미세한 지연 시간(Latency)이 발생할 수 있다. 따라서 CPU Governor 설정을 performance 모드로 변경해, 항상 최대 클럭이 유지되도록 강제했다.
QTimer vs PREEMPT_RT 성능 비교
☑ QTimer는 내부의 QEventLoop 구조로 인해 Linux Basic Kernel 보다 Jitter가 클 것이다.
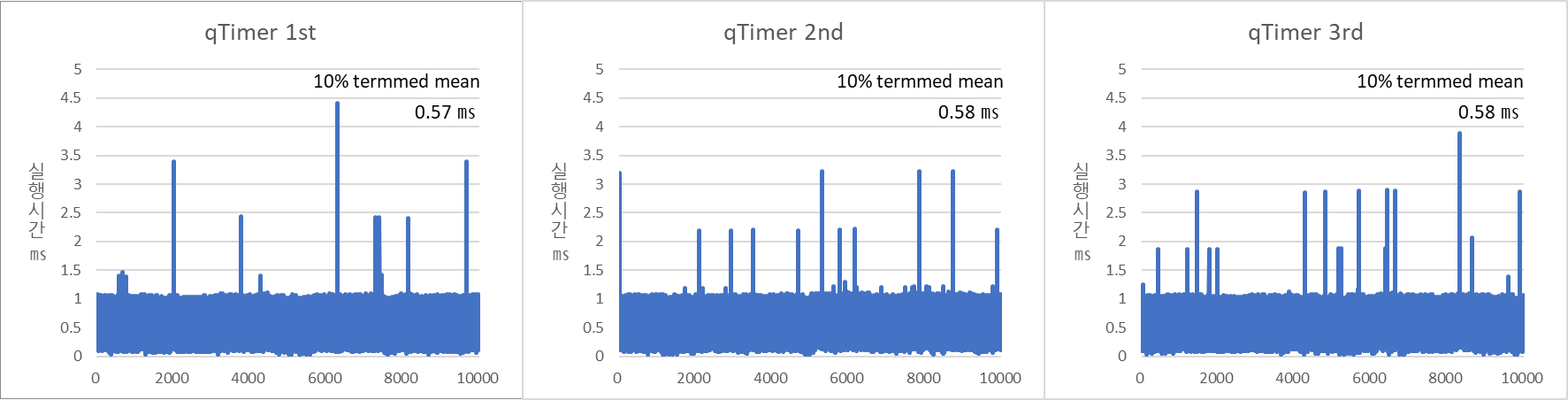
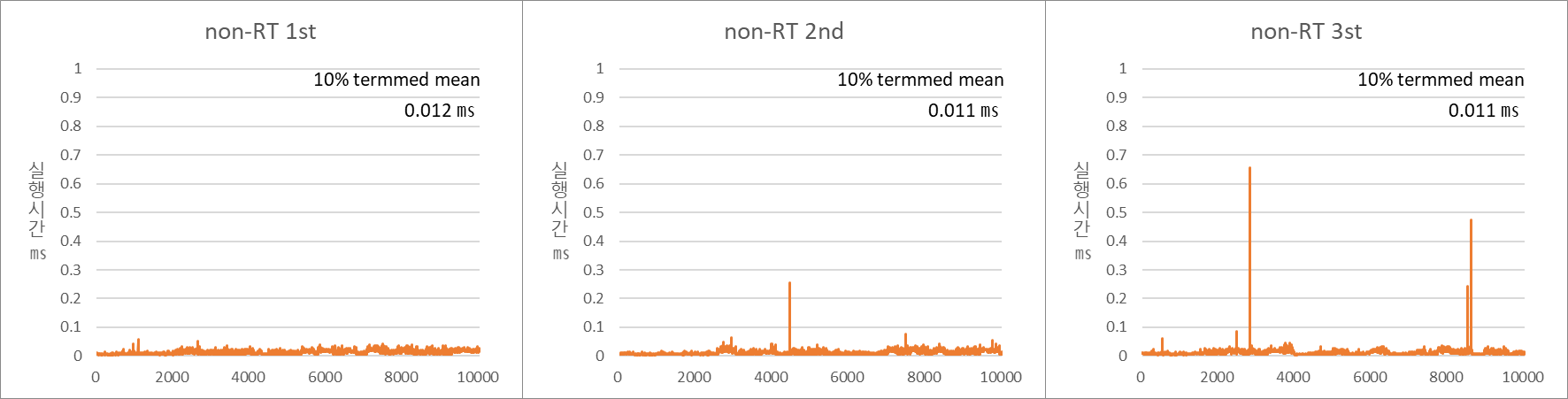
두 호출 방식의 결과는 예상대로 압도적인 차이가 발생했다.
이상치에 해당하는 Jitter를 제외(상하위 10%를 제외)한 평균시간에서도 약 50배 가까이 차이가 확인되었다.
- QTimer 평균 지연 = 0.576987 ㎳
- Linux non-RT Kernel 평균 지연 = 0.011389 ㎳
☑ CPU부하로 인해 QTimer와 non-RT Kernel의 Jitter는 들쭉날쭉할 것이다
또한 non-RT kernel 환경의 테스트 결과를 보면, 시스템 컨디션에 따라 Jitter가 발생하는 것을 확인할 수 있었다.
첫 번째 측의 경우 운이 좋게도 OS 스케줄러 간섭 없이 매끄럽게 통과했지만,
세 번째 측정 결과(3rd)에서는 최대 0.65 ms까지 값이 튀는 것을 볼 수 있었다.
이는 Inturrupt 발생 시점부터 Task 실행까지 운이 좋으면 11㎲, 운이 나쁠 때는 650㎲까지 지연될 수 있음을 의미한다.
☑ RT Kernel의 Jitter는 시스템 부하에서도 안정적이어야 한다.

이 글의 목적인 PREEMPT_RT Kernel에서는 Jitter가 확실하게 잡혀 안정적으로 프로그램이 실행되는 것을 확인할 수 있었다.

non-RT 환경에서 실행 시간의 변동성이 가장 컸던 세 번째 케이스를 PREEMPT_RT 위에서 돌렸을 때,
평균 11㎲ 최악의 경우 70㎲ 실행속도를 측정했다.
순간적으로 650㎲ 까지 지연됐던 범용 커널에 비해 훨씬 신뢰도 높고 예측 가능한 움직임을 보여주었다.
회고
데이터의 처리 성능(Throughput)이 중요한 비전(Vision) 프로그램을 다룰 때 주로 테스트 설계를 고민해 왔었는데,
오랜만에 이렇게 마이크로초(㎲) 단위의 응답성을 다투는 정밀도 테스트를 설계하고 검증해 보니 시스템 코어 개발마의 색다른 재미를 느낄 수 있었다.
내심 "나노초 단위까지 제어할 수 있는 결과를 볼 수 있지 않을까?"라는 기대와는 달라 아쉬운 점도 있었지만,
무거운 범용 운영체제인 Linux에서 RTOS가 아님에도 커널 패치로 이 정도의 성능을 끌어낸다는 점에서 PREEMPT_RT 기술의 우수성을 엿볼 수 있었다.
CPU Isloation과 IRQ가 RT-CPU를 방해하지 않도록 하는 IRQ Affinity 조정방법을 통해 실행시간을 좀 더 단축할 수 있겠지만,
이번 프로젝트의 PoC 차원에서 진행된 테스트 프로그램의 결과물로는 이 정도로 만족스럽다.
직접 공부해서 다음 글로 정리해 보려고 합니다.
'개발' 카테고리의 다른 글
| ROS2를 처음 분석하며 정리한 핵심 개념 - DDS, QoS, ROS Architecture (0) | 2026.04.29 |
|---|---|
| C++ Preemptive Task Scheduler 구현 및 성능 비교 (Windows · Linux · Linux PREEMPT_RT) (0) | 2026.04.18 |
| Windows 한글 계정명에서 발생하는 CMake 빌드 에러 원인과 해결 방법 (0) | 2026.03.31 |
| Antigravity 구독 취소 방법(환불정책) (3) | 2026.03.26 |
| Real-Time, RTOS, PREEMPT_RT, CPU Isolation 개념 정복 - 실시간 처리 (0) | 2026.03.19 |